
2. pandas 객체를 이용한 시각화
"""
형식) obj.plot(param) : 오브젝트.plot( - 파라미터 넣기 - )
obj : Series(1차원), DataFrame(2차원)
"""
import pandas as pd
import numpy as np
# 1. Series 객체 시각화
ser = pd.Series(np.random.randn(10)) # 난수 10개로 series 객체 생성
ser
ser.plot()
ser.plot(color = 'g') # green

# 2. DataFrame 객체 시각화
df = pd.DataFrame(np.random.randn(10, 4),
columns = ['one','two','three','four']) # 10행 4열 랜덤데이터 -> 총 40개의 데이터 생성
df

# 기본 차트
df.plot() # default : line 그래프 (칼럼별로 그려짐)

# 막대차트(세로막대)
df.plot(kind='bar', title='.. bar chart ..')

# 막대차트(가로막대)
df.plot(kind='barh', title='.. bar chart ..')

'''
tips.csv 파일 이용
'''
tips = pd.read_csv("../data/tips.csv")
tips.info()
tips.head()
# 요일(day) vs 규모(size) 범주 확인
tips['day'].unique()
# ['Sun', 'Sat', 'Thur', 'Fri']
tips['size'].unique()
# [2, 3, 4, 1, 6, 5]
# 교차분할표 : row(day) vs column(size)
tips_tab = pd.crosstab(tips['day'], tips['size'])
tips_tab

tips_tab.shape # (4, 6)
# 교차분할표에서 원하는 행/열 데이터 꺼내기
# loc 속성 : label
tips_tab.loc['Fri':'Sun', 2:4]
# iloc 속성 : integer
tips_tab.iloc[:3, 1:4]
# 둘 다 결과는 다음과 같음
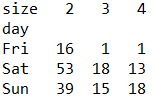
tips_sub = tips_tab.loc[:, 2:6]
tips_sub

# 이산변수 : 가로막대 누적형 차트
tips_sub.plot(kind='barh', stacked=True, title='day and size columns')

# 이산변수 : pie 차트
size_val = tips['size'].value_counts()
size_val
size_val.plot(kind='pie')

'''
dataset.csv 파일 이용
- 산점도 시각화
'''
data = pd.read_csv("../data/dataset.csv")
data.info()
'''
RangeIndex: 217 entries, 0 to 216
Data columns (total 7 columns):
'''
dataset = data[['resident', 'gender', 'age', 'price']] # 숫자형 데이터만 사용
dataset.head()
dataset['age']
dataset['price']
import matplotlib.pyplot as plt
# 연속형 : 산점도
plt.scatter(x=dataset['age'], y=dataset['price'])

# 연속형 :histogram
plt.hist(dataset['age'])

plt.hist(dataset['price'])
'''
iris.csv 파일 이용
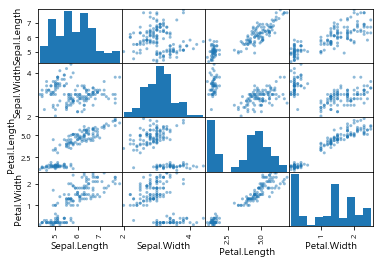
- 산점도 matrix 시각화
'''
iris = pd.read_csv("../data/iris.csv")
iris.info()
pd.plotting.scatter_matrix(iris.iloc[:, :4]) # iris 데이터에서 4개의 칼럼끼리 matrix 산점도
'''
3차원 산점도 시각화
'''
from mpl_toolkits.mplot3d import Axes3D
x = iris['Sepal.Length']
y = iris['Sepal.Width']
z = iris['Petal.Length']
cdata = [ ]
for s in iris['Species'] :
if s == 'setosa' :
cdata.append(1)
elif s == 'versicolor' :
cdata.append(2)
else :
cdata.append(3)
fig = plt.figure(figsize = (10, 5))
chart = fig.add_subplot(1,1,1, projection='3d')
chart.scatter(x, y, z, c=cdata)
chart.set_xlabel('Sepal.Length')
chart.set_ylabel('Sepal.Width')
chart.set_zlabel('Petal.Length')

--------------------------------------------------- example ---------------------------------------------------
'Python 과 머신러닝 > II. 데이터처리 문법' 카테고리의 다른 글
| [Python 머신러닝] 3장. 그룹화 (group by & apply) (0) | 2019.10.18 |
|---|---|
| [Python 머신러닝] 2장. 차트 시각화 - (3)시계열 데이터 (4) | 2019.10.18 |
| [Python 머신러닝] 2장. 차트 시각화 - (1)matplot (0) | 2019.10.17 |
| [Python 머신러닝] 1장. Pandas - (2) 기술통계, DataFrame 병합 (0) | 2019.10.16 |
| [Python 머신러닝] 1장. Pandas - (1) Series와 DataFrame (0) | 2019.10.16 |




댓글