[Python 머신러닝] 8장. 군집분석 (Cluster Analysis)

군집분석이란?
서로 유사한 정도에 따라 다수의 객체를 군집으로 나누는 작업 또는 이에 기반한 분석을 의미한다.
- 유사도가 높은 데이터끼리 그룹화 (대표적으로 유클리드 거리식 이용)
- 계층형 클러스터링과 비계층형 클러스터링으로 분류
- 주요 알고리즘 : k-means, hierarchical
> 군집분석의 특징
- 종속변수(y변수)가 없는 데이터 마이닝 기법 (비지도 학습)
- 유클리드 거리 기반 유사 객체 묶음 (유사성 = 유클리드 거리)
- 전체적인 데이터 구조를 파악하는데 이용
- 분석결과에 대한 가설 검정 없음 (타당성 검증 방법 없음)
- 계층적 군집분석(탐색적), 비계층적 군집분석(확인적)
- 고객 DB -> 알고리즘 적용 -> 패턴 추출(rule) -> 근거리 모형으로 군집 형성
- 척도 : 등간, 비율척도 => 명목척도를 만듦

1) 유클리드 거리
- 두 점 사이의 거리를 계산하는 방법
- 이 거리를 이용하여 유클리드 공간 정의


2) 계층적 군집분석 (hierarchical)
- 유클리드 거리를 이용한 군집분석 방법
- 계층적으로 군집 결과 도출
- 탐색적 군집분석
- 계층적 군집분석의 결과
=> 덴드로그램 (Dendrogram) : 표본들이 군을 형성하는 과정을 나타내는 나무 형식의 그림
- 군집 수는 사용자가 정할 수 있음 (2집단, 3집단, ... 등)

- 군집화 방식
① 단일기준결합방식 : 각 군집에서 중심으로부터 거리가 가까운 것 1개씩 비교하여 가장 가까운 것끼리 군집화
② 완전기준결합방식 : 각 군집에서 중심으로부터 가장 먼 대상끼리 비교하여 가장 가까운 것끼리 군집화
③ 평균기준결합방식 : 한 군집 안에 속해 있는 모든 대상과 다른 군집에 속해있는 모든 대상의 쌍 집합에 대한 거리를 평균 계산하여 가장 가까운 것끼리 군집화

3) 비계층적 군집분석 (k-Means)
- 계층적 군집분석보다 속도 빠름
- 군집의 수를 알고 있는 경우 이용
- k는 미리 정하는 군집 수
- 확인적 군집분석
- 계층적 군집화의 결과에 의거하여 군집 수 결정
- 변수보다 관측대상 군집화에 많이 이용
- 군집의 중심(Cluster Center)은 사용자가 정함
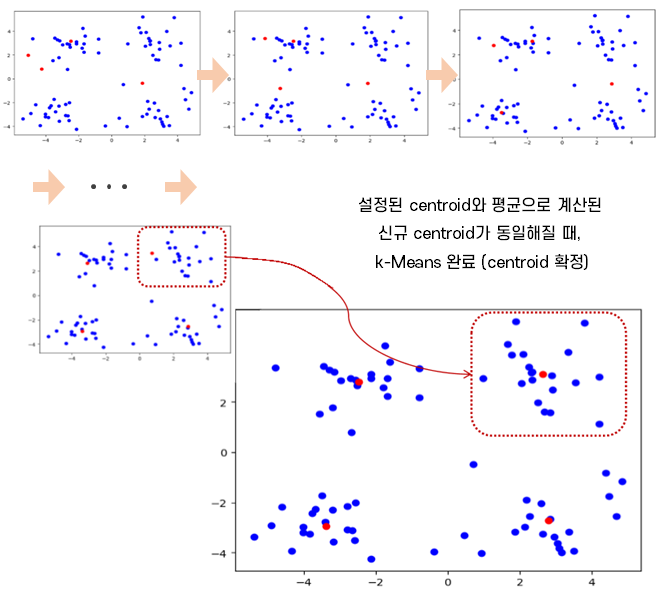
> k-평균(k-Menas) 군집분석 알고리즘
① k값을 초기값으로, k개의 centroid 선정 (랜덤)
② 각 데이터 포인터를 가장 가까운 centroid에 할당
③ centroid에 할당된 모든 데이터 포인트의 중심 위치 계산 (centroid 재조정)
④ 재조정된 centroid와 가장 가까운 데이터 포인트 할당
⑤ centroid 재조정이 발생되지 않을 때까지 ③, ④단계 반복
<실습한 내용>
1. hierachical (hierarchy)
2. kMeans 실습(1)
3. kMeans 실습(2)
1. hierachical (hierarchy)
"""
계층적 군집분석
- 유클리드 거리계산식 이용
- 상향식(Bottom-up)으로 군집을 형성
"""
import pandas as pd # dataset load
from sklearn.datasets import load_iris
# 계층적 군집 model
from scipy.cluster.hierarchy import linkage, dendrogram
# 1. dataset load
iris = pd.read_csv("../data/iris.csv")
iris.info()
cols = list(iris.columns)
iris_x = iris[cols[:4]]
iris_x.head()
iris['Species'].value_counts() # 'Species' : y변수
'''
versicolor 50
virginica 50
setosa 50
'''
# 2. y변수 수치화
X, y = load_iris(return_X_y=True)
# 사이킷런 라이브러리에서 제공하는 데이터셋을 불러오면 범주값을 숫자로 받을 수 있음
y # 0,1,2로 구성됨
labels = pd.DataFrame(y, columns = ['labels'])
# df = df + df
irisDF = pd.concat([iris_x, labels], axis = 1)
irisDF.head()
irisDF.tail() # x변수들과 수치화된 y변수(labels)로 데이터프레임 만들어진 것을 확인

# 3. 계층적 군집분석 model
clusters = linkage(y=irisDF, method='complete', metric='euclidean')
clusters
clusters.shape # (149, 4)
'''
연결방식
1. 단순연결방식(single)
2. 완전연결방식(complete)
3. 평균연결방식(average)
'''
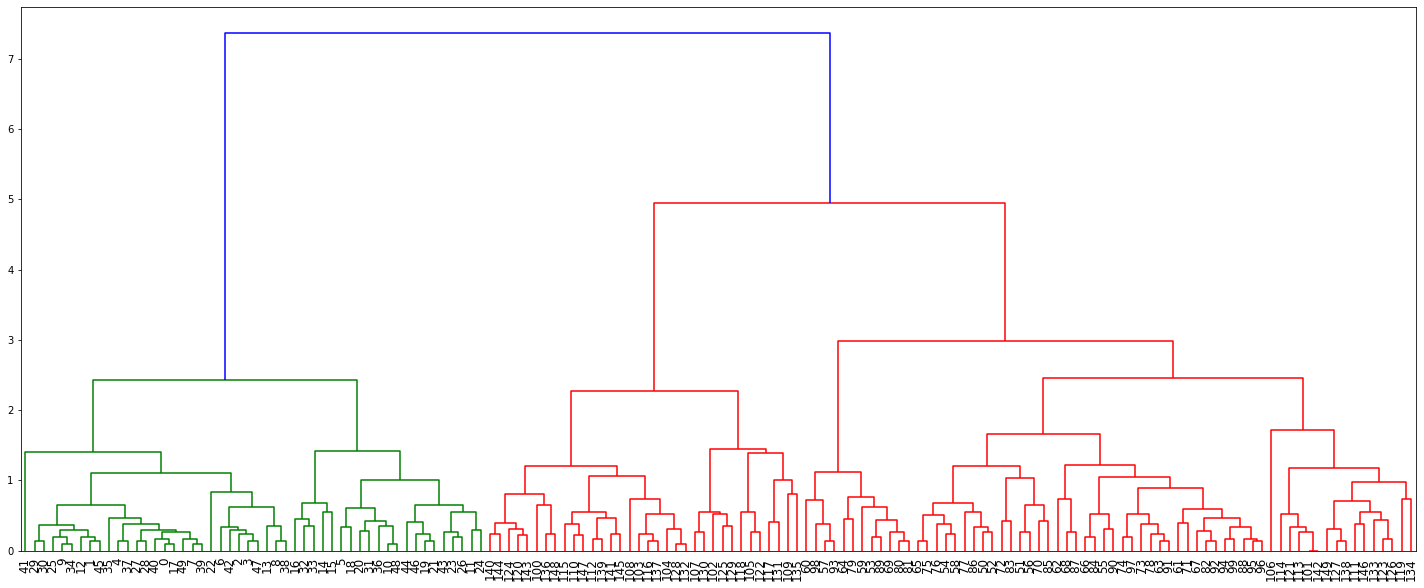
# 4. 덴드로그램 시각화 : 군집수 결정
import matplotlib.pyplot as plt
plt.figure( figsize = (25, 10) )
dendrogram(clusters, leaf_rotation=90, leaf_font_size=12,)
# leaf_rotation=90 : 글자 각도
# leaf_font_size=20 : 글자 사이즈
plt.show()
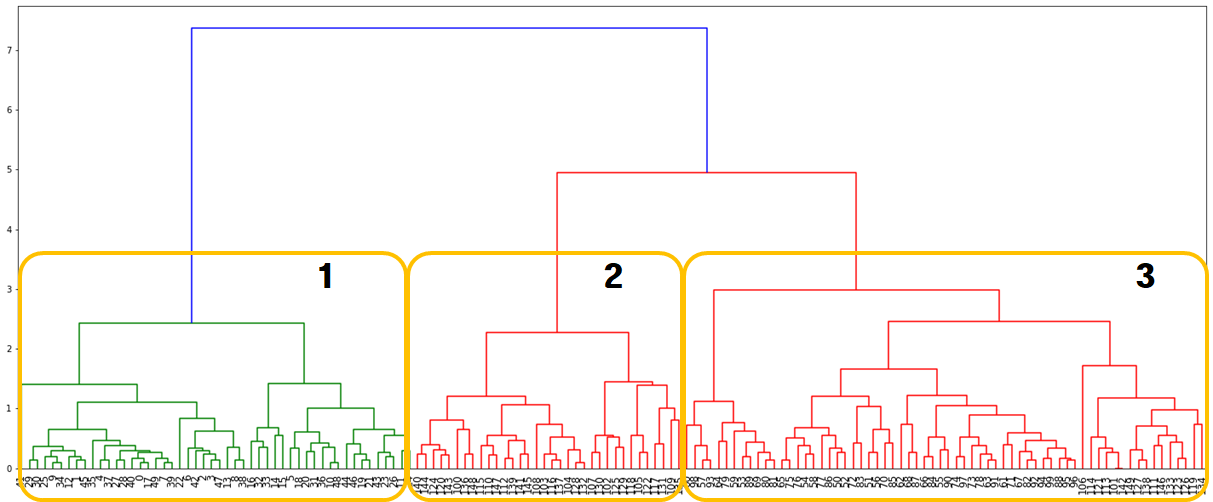
# 5. 클러스터링(군집) 결과
from scipy.cluster.hierarchy import fcluster # 지정한 클러스터 자르기
cut_tree = fcluster(clusters, t=3, criterion='distance')
cut_tree # prediction
labels = irisDF['labels'] # 정답
df = pd.DataFrame({'pred':cut_tree, 'labels':labels})
con_mat = pd.crosstab(df['pred'], df['labels'])
con_mat
'''
labels 0 1 2
pred
1 50 0 0
2 0 0 34
3 0 50 16
'''
# irisDF에 군집 예측치 추가
irisDF.head()
irisDF['cluster'] = cut_tree
irisDF.head()

# 클러스터 단위 산점도 시각화
plt.scatter(x=irisDF['Sepal.Length'], y=irisDF['Petal.Length'], c=irisDF['cluster'])
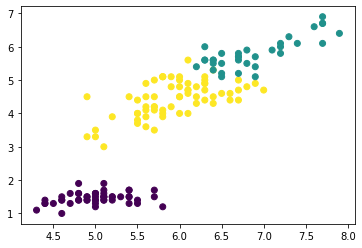
# 클러스터 빈도수
irisDF['cluster'].value_counts()
'''
3 66
1 50
2 34
'''
# 각 클러스터별 통계(평균)
cluster_g = irisDF.groupby('cluster')
cluster_g.mean()
'''
Sepal.Length Sepal.Width Petal.Length Petal.Width labels
cluster
1 5.006000 3.428000 1.462000 0.246000 0.000000
2 6.888235 3.100000 5.805882 2.123529 2.000000
3 5.939394 2.754545 4.442424 1.445455 1.242424
'''
2. kMeans 실습(1)
"""
kMeans 알고리즘
- 확인적인 군집분석
- 군집 수 k를 알고 있는 경우 이용
"""
import pandas as pd # dataset load
from sklearn.cluster import KMeans # model
import matplotlib.pyplot as plt # 시각화
# 1. dataset load
# 위와 똑같은 iris.csv 파일 이용
iris = pd.read_csv("../data/iris.csv")
iris.info()
irisDF = iris[['Sepal.Length', 'Petal.Length']] # 두 개의 칼럼만 이용
irisDF.head()
# 2. 비계층적 군집 분석 model
model = KMeans(n_clusters=3, random_state=0, algorithm='auto')
# n_clusters=3 : 군집의 개수 (k) (이미 알고 있음)
# random_state=0 : seed 역할 (모델을 일정하게 생성 = 랜덤X)
model.fit(irisDF)
# 3. 클러스터링(군집) 결과
pred = model.predict(irisDF)
pred
len(pred) # 150 (관측치 개수만큼 예측치 생성됨)
# 4. 군집결과 시각화
plt.scatter(x=irisDF['Sepal.Length'], y=irisDF['Petal.Length'], c=pred)
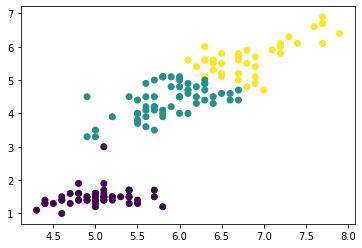
# 군집별 중앙값
centers = model.cluster_centers_
centers
'''
array([[5.00784314, 1.49215686],
[5.87413793, 4.39310345],
[6.83902439, 5.67804878]])
'''
# 군집별 중앙값 시각화
plt.scatter(x=centers[:,0], y=centers[:,1], marker='D', c='r')
# marker='D', c='r' : 마커 모양은 Diamond, 색깔은 red
plt.show()

# 군집결과와 중앙값 함께 시각화
plt.scatter(x=irisDF['Sepal.Length'], y=irisDF['Petal.Length'], c=pred)
plt.scatter(x=centers[:,0], y=centers[:,1], marker='D', c='r')
plt.show()
# 블럭 실행

3. kMeans 실습(2)
"""
kMeans 알고리즘
- testSet.txt 파일 데이터셋 이용
"""
import pandas as pd
from sklearn.cluster import KMeans # model
import matplotlib.pyplot as plt # 시각화
import numpy as np # dataset
# testSet 데이터는 다음과 같은 형태로 입력되어 있음

# dataset 생성 함수
def loadDataSet(fileName) :
rows = [] # 전체 행(80개)
f = open(fileName, mode='r')
lines = f.readlines() # 줄단위 전체 행 읽기
for row in lines : # 줄 단위 읽기 : 1.658985 4.285136
line = row.split('\t') # '1.658985' '4.285136'
row = [] # 1줄 행
for l in line :
row.append( float(l) ) # ['1.658985', '4.285136']
rows.append(row) # [['1.658985', '4.285136'], .... ]
return np.array(rows) # 2차원(80, 2) 행렬 구조로 return
# 1. 함수 호출
dataset = loadDataSet("../data/testSet.txt")
dataset.shape # (80, 2)
type(dataset) # numpy.ndarray
dataset
dataset[:10, :] # 10행
plt.plot(dataset[:,0], dataset[:,1], 'go') # 0번째 열은 x값, 1번째 열은 y값, 'go' : green 색깔의 o 모양 마커
plt.show()
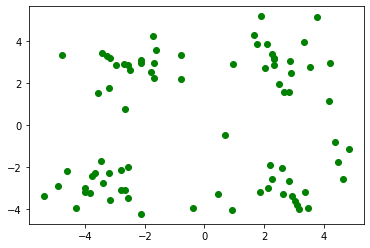
# 2. df 생성
dataDF = pd.DataFrame(dataset, columns = ['x', 'y'])
dataDF.info()
# 3. kMeans model
model = KMeans(n_clusters=4, algorithm='auto') # k = 4
model.fit(dataDF)
# kMeans 예측치
pred = model.predict(dataDF)
pred # 0~3, 총 4개의 도메인으로 군집 형성
plt.scatter(x=dataDF['x'], y=dataDF['y'], c=pred)

# 각 군집의 중앙값
centers = model.cluster_centers_
centers
plt.scatter(x=centers[:,0], y=centers[:,1], marker='D', c='r')
plt.show()
# 예측치부터 블럭실행

# 4. 원형 데이터에 군집 예측치 추가
dataDF['cluster'] = pred
dataDF.head()
